You can copy the code from this blog and run it on Google Colab or Amazon SageMaker Studio Lab. These platforms offer free GPU support and a ready-to-use environment, making it easy to experiment with transformer models.



The most basic object in the 🤗 Transformers library is the pipeline() function. It connects a model with its necessary preprocessing and postprocessing steps, allowing us to directly input any text and get an intelligible answer.
![[{'label': 'POSITIVE', 'score': 0.9998854398727417}, {'label': 'POSITIVE', 'score': 0.9938306212425232}, {'label': 'NEGATIVE', 'score': 0.9995132684707642}]](https://cdn.myikas.com/images/0f9bde95-a9e9-46c8-bfae-7a061b77d97a/3820486a-efcc-4379-b040-0224dd35d4d7/image_1080.webp)
This code uses Hugging Face's pipeline function to create a sentiment analysis model. It processes specified sentences to predict whether each sentence expresses a positive, negative, or neutral sentiment and then prints the results.
Note: By default, if no model is specified, the pipeline downloads distilbert-base-uncased-finetuned-sst-2-english.
By default, this pipeline selects a particular pretrained model that has been fine-tuned for sentiment analysis in English. The model is downloaded and cached when you create the classifier object.
Using a Specific Model
![[{'label': 'LABEL_2', 'score': 0.991532027721405}, {'label': 'LABEL_1', 'score': 0.7582790851593018}, {'label': 'LABEL_0', 'score': 0.9803597331047058}]](https://cdn.myikas.com/images/0f9bde95-a9e9-46c8-bfae-7a061b77d97a/463fcdf7-078b-4542-a5e3-8a8ebde532a9/image_1080.webp)
- Pipeline Creation:The code imports the pipeline function from the Transformers library and creates a sentiment analysis pipeline using the "cardiffnlp/twitter-roberta-base-sentiment" model.
- Processing Input:A list of sentences is defined. The pipeline (named classifier) is then applied to these sentences to analyze their sentiment.
- Output Explanation:The output is a list of dictionaries. Each dictionary contains: label and score.
- label: A value such as LABEL_2, LABEL_1, or LABEL_0, which typically correspond to positive, neutral, and negative sentiments, respectively.
- score: A confidence score between 0 and 1 indicating how sure the model is about its prediction.
There are three main steps involved when you pass some text to a pipeline:
1.The text is preprocessed into a format the model can understand.
2.The preprocessed inputs are passed to the model.
3.The predictions of the model are post-processed, so you can make sense of them.
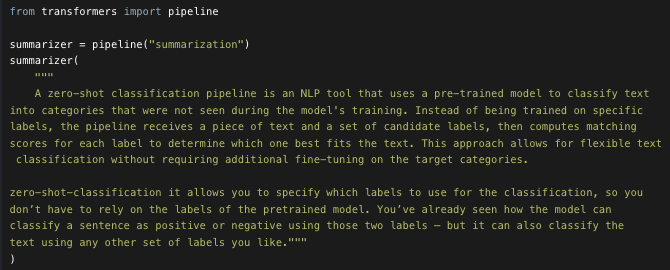
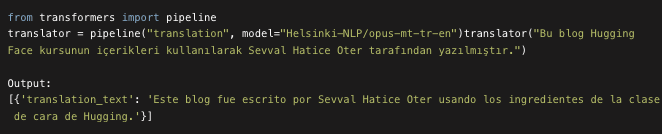
Some of the currently available pipelines are: feature-extraction (get the vector representation of a text) , fill-mask, ner (named entity recognition), question-answering, sentiment-analysis,summarization, text-generation, translation, zero-shot-classification etc.
A zero-shot classification pipeline is an NLP tool that uses a pre-trained model to classify text into categories that were not seen during the model's training. Instead of being trained on specific labels, the pipeline receives a piece of text and a set of candidate labels, then computes matching scores for each label to determine which one best fits the text. This approach allows for flexible text classification without requiring additional fine-tuning on the target categories.
It allows you to specify which labels to use for the classification, so you don’t have to rely on the labels of the pretrained model.
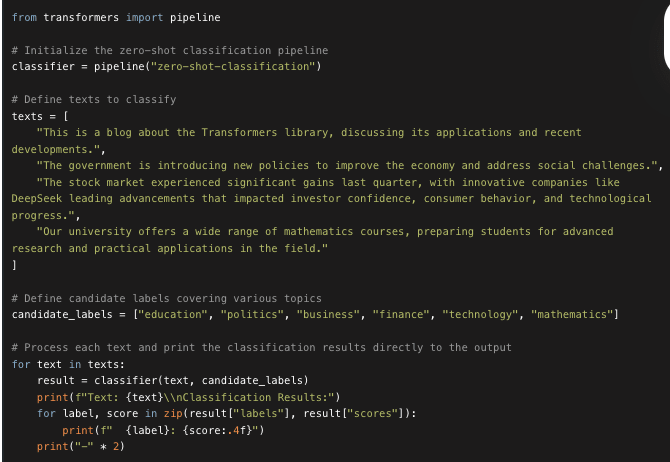
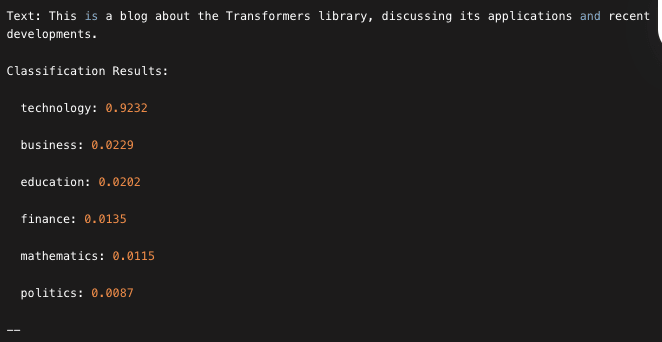
The code initializes a zero-shot classification pipeline to classify texts into predefined candidate labels. It processes each text by evaluating how well each candidate label matches the content and then prints the ranked labels along with their confidence scores. This approach allows you to dynamically assess text content against multiple topics without having to fine-tune a model for specific categories.
The zip function pairs each element from result["labels"] with the corresponding element from result["scores"]. This allows you to iterate over both lists simultaneously in the loop, so that for every label you can directly access its associated score.
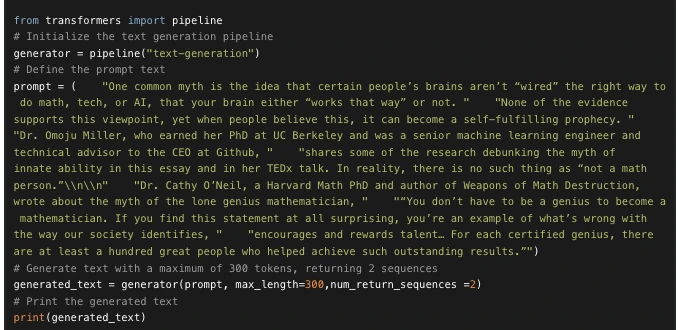
The main idea here is that you provide a prompt and the model will auto-complete it by generating the remaining text. This is similar to the predictive text feature that is found on many phones. Text generation involves randomness, so it’s normal if you don’t get the same results as shown .
Prompt text:There's no such thing as not a math person,fast.ai. 👀
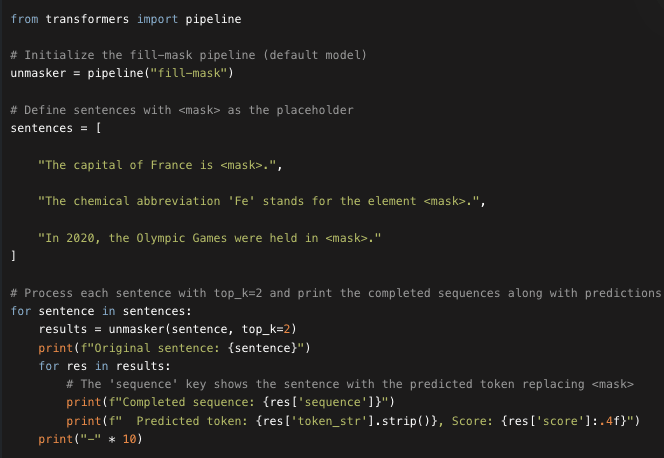
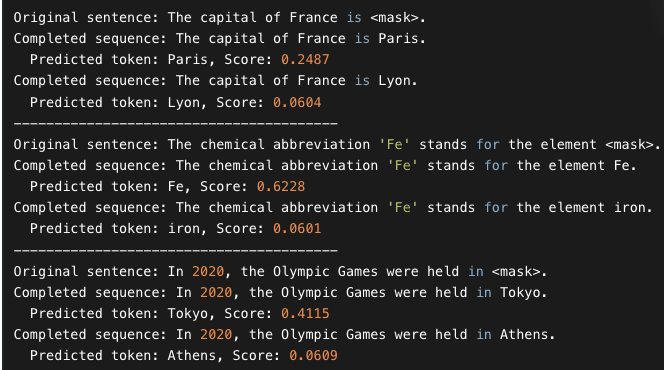
The top_k argument controls how many possibilities you want to be displayed. Note that here the model fills in the special word, which is often referred to as a mask token.
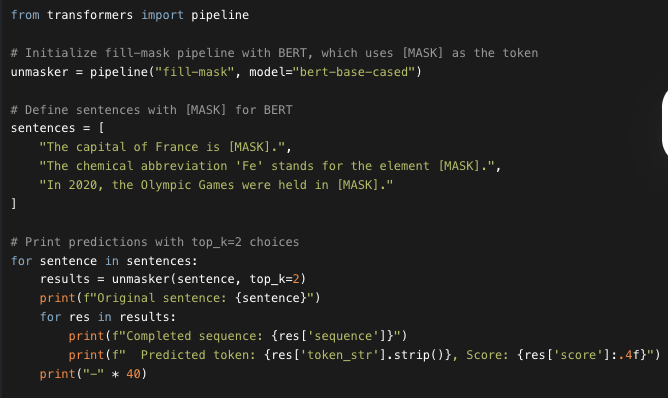
For example for model "bert-base-cased" we use [MASK]. As you can see:
Using BERT with a Specific Mask Token
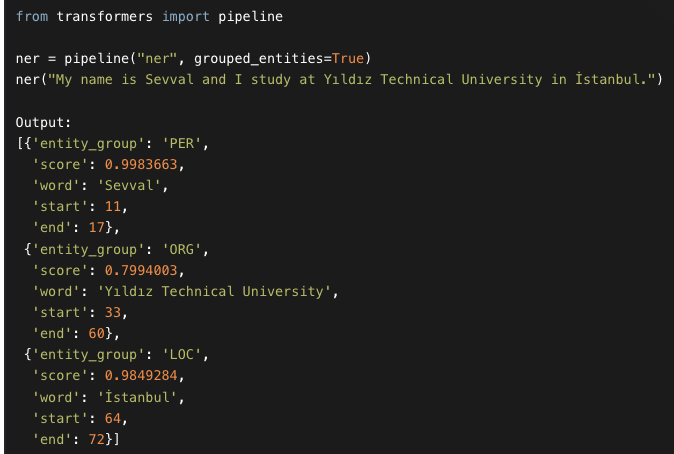
Named Entity Recognition (NER) identifies entities like persons, organizations, and locations within text. The grouped_entities=True parameter groups tokens that form multi-token entities (e.g., "New York" or "Yıldız Technical University") into a single coherent entity, making the output more human-readable and meaningful.

Original text: The Batch Issue 289,DeepLearning.AI 👀
![[{'summary_text': ' A drone from Skyfire AI was credited with saving a police officer’s life after a dramatic 2 a.m. traffic stop . The officer had pulled over a vehicle and had not been heard from since . The drone rapidly located the officer and the driver of the vehicle .'}]](https://cdn.myikas.com/images/0f9bde95-a9e9-46c8-bfae-7a061b77d97a/34b12398-5b68-4b4a-9223-66393dbd97d9/image_1080.webp)